지난 포스트의 순서도에서 #1으로 표시한 '명령어 결과파일 읽어오기'와 #2으로 표시한 '데이터시트 구현'에 대해서 이야기 하고자 합니다.
1. 명령어 결과파일 읽어오기
1) 코드
@Override
public List<String[]> getDataFromTargetFile(String filePath) throws IOException {
// (1) Target file Object generate.
File f = new File(filePath);
List<String[]> fileValues = new ArrayList<>();
if (f.isFile()) {
try (BufferedReader br = Files.newBufferedReader(Paths.get(f.getAbsolutePath()),
Charset.forName("UTF-8"))) {
String line = "";
while ((line = br.readLine()) != null) {
if (Pattern.compile("[0-9\s]+").matcher(line).matches()) {
fileValues.add(line.trim().split("\s+"));
}
}
}
}
return fileValues;
}2) 설명
$ vmstat 1 >> textfile.txt와 같은 커맨드를 실행하면 명령어의 결과를 텍스트 파일로 출력할 수 있습니다.
출력된 명령어의 결과는 아래와 같습니다.

첫번째 행과 두번째 행은 수치가 무엇을 의미하는지가 출력되며 3번째 행 부터는 서버의 상태가 수치로 출력됩니다.
수치가 20번 출력된 후에는 첫번째 행과 두번째 행과 같은 내용이 출력된 후 다시 수치가 출력되는 방식으로 반복됩니다.
첫번째 두번째 행이후에 모두 수치라면 파일을 1줄씩 읽어올때 2번째줄까지만 무시하고 3번째 행부터 읽어오면 되겠지만,
수치의 의미가 반복되고 있으므로 결과 파일을 읽어올때 수치데이터만을 추려내는 작업이 필요합니다.
수치 데이터 행의 표시 규칙을 보면 아래와 같다는 것을 알 수 있습니다.
(1) 공백과 수치만으로 이루어져 있음.
(2) 각 값은 공백으로 구분되어 있으며, 행의 앞뒤에 공백이 있음.
(3) 각 열의 항목에 해당하는 행의 값은 Not null이며 0이라도 값이 들어감.
위 규칙을 기반으로 아래의 내용을 구현했습니다.
(1) 공백과 수치만으로 이루어진 행을 정규표현식으로 추려내기
(2) 행의 앞뒤에 공백제거후 공백을 구분자로하여 분자열을 잘라내어 배열로 만들기
(3) 만든 배열을 리스트에 집어넣기
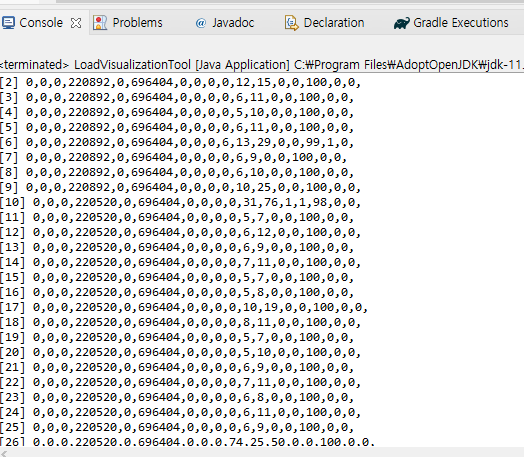
3) 결과
콘솔에 결과 값을 출력해 보았습니다.
2. 데이터시트 구현
1) 코드
public Sheet makeDataSheet(Workbook excelWorkbook, List<String[]> fileValues) throws ParseException {
XSSFWorkbook workbook = (XSSFWorkbook) excelWorkbook;
// Make Data Sheet
XSSFSheet sheet = workbook.createSheet("Data");
// Generate First Row
// procs,-----------memory----------,---swap--,-----io----,-system--,------cpu-----
List<int[]> locations = ContextVmstatAMI.D_00_FORMAT_LOCATIONS;
for (int[] location : locations) {
sheet.addMergedRegion(new CellRangeAddress(location[0], location[1], location[2], location[3]));
}
CellStyle headerStyle = workbook.createCellStyle();
headerStyle.setFillBackgroundColor(IndexedColors.BLACK.getIndex());
headerStyle.setAlignment(HorizontalAlignment.CENTER);
Cell cell = null;
List<String> values = ContextVmstatAMI.D_00_VALUES;
List<int[]> valueLocations = ContextVmstatAMI.D_00_VALUE_LOCATIONS;
for (int i = 0; i < values.size(); i++) {
cell = getCell(sheet, valueLocations.get(i)[0], valueLocations.get(i)[1]);
cell.setCellValue(values.get(i));
cell.setCellStyle(headerStyle);
}
// Generate Second Row
// r,b,swpd,free,buff,cache,si,so,bi,bo,in,cs,us,sy,id,wa,st
List<String> valuesSecond = ContextVmstatAMI.D_01_VALUES;
List<int[]> locationsSecond = ContextVmstatAMI.D_01_VALUE_LOCATIONS;
for (int i = 0; i < valuesSecond.size(); i++) {
getCell(sheet, locationsSecond.get(i)[0], locationsSecond.get(i)[1])
.setCellValue(valuesSecond.get(i));
}
// Generate Data Row
int addDatetime = 0;
Date date = sdfForm1.parse(startDateTime);
Calendar cal = Calendar.getInstance();
cal.setTime(date);
int fileValueCount = fileValues.size();
int startNumOfResultValueDatas = 2; // Because 'result value datas' are going to input from the second row.
for (int rowNum = 0; rowNum < fileValueCount; rowNum++) {
String[] line = fileValues.get(rowNum);
// step.1 Output Datetime
cal.add(Calendar.SECOND, addDatetime + interval);
getCell(sheet, startNumOfResultValueDatas, 0).setCellValue(sdfForm1.format(cal.getTime()));
// step.2 Output result value.
for (int cellNum = 1; cellNum <= line.length; cellNum++) {
getCell(sheet, startNumOfResultValueDatas, cellNum).setCellValue(Double.parseDouble(line[cellNum-1]));
}
startNumOfResultValueDatas++;
}
return sheet;
}
2) 설명
먼저 이 프로젝트에서 엑셀파일을 다룰때는 Java로 엑셀파일을 다룰때 가장 쉽게 접할 수 있는 라이브러리인 Apache poi를 사용해서 구현하기로 했습니다.
Apache Poi를 기본조작 법에 대한 설명은 검색하면 많은 자료가 나오므로 생략하겠습니다.
제가 생각한 데이터 시트의 이미지는 표와 같은 것으로 구체적인 설명은 아래와 같습니다.
(1) 첫행과 두번째 행에는 수치의 의미가 입력될 것
(2) 3번째 행부터 수치데이터가 입력될 것
(3) 수치데이터의 첫번째 컬럼에는 명령어의 출력시간이 (랩타입) 출력될 것
※ 아마도 awk를 사용하면 명령어 출력시부터 랩타입이 출력될 것 같긴한데....
사실 이 프로젝트를 하기 전까지는 몰랐었는데 vmstat명령어는 결과값이 리눅스 배포판별로 다른 결과 값이 나온다는것을 새롭게 알게 되었습니다.
현재 제가 주로 사용하는 리눅스 배포판은 AMI이므로 AMI의 vmstat결과값의 정보를 변수로 모아둔 Context파일을 만들어서 사용하기로 했습니다.
데이터 시트의 첫줄과 두번째줄는 Context변수에 저장되어있는 값을 입력했습니다.
리스트에 담겨있는 수치데이터의 배열수 만큼 반복하여 데이터시트의 3번째 줄부터의 값을 입력 입력했습니다.
수치데이터의 첫번째 컬럼에는 기동변수로 입력된 명령어 시작시간과 랩타임을 사용하여 명령어 출력시간을 입력합니다.
수치데이터의 두번째 컬럼부터 마지막까지는 수치데이터의 배열에 있는 값을 입력합니다.
3) 결과
출력된 데이터 시트입니다.

댓글